Unification, in a nutshell, is the matching of two patterns.
It solves the problem “given two patterns, that might both
contain variables, find values for those variables that will
make the two patterns equal.”
Our pattern matcher from the previous section is a good jumping
off point for implementing true unification. In fact it
has most of the things we'll need already in place. The next
section discusses the modifications we will need to make to
it.
17.3.1. A Perl Unifier
This unifier can solve a broader class of problems than
a simple pattern matcher can. For example given the two patterns:
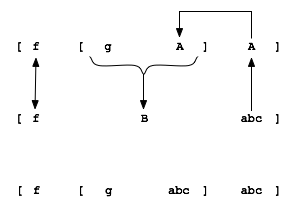
['f', ['g', 'A'], 'A']
and
['f', 'B', 'abc']
It can correctly deduce:
A => 'abc',
B => ['g', 'abc']
You can see the process graphically in Figure 17.2.
The variable 'A' unifies with the term 'abc'
while the variable 'B' unifies with the compound term
['g', 'A'], where 'A' is provided with a value
'abc' from the previous unification.
Unification is capable of even more complex resolutions,
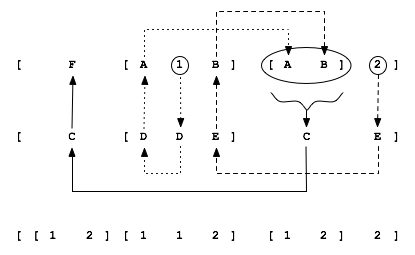
for example it can unify (ommitting quotes for brevity this time)
[F, [A, 1, B], [A, B], 2]
with
[C, [D, D, E], C, E]
To show that
A = 1B = 2C = [1, 2]D = 1E = 2F = [1, 2]
You can see this in action in
Figure 17.3
if you just follow the differently styled arrows starting
from the three ringed nodes in the figure as they propogate
information around.
This unifier has additional feature: the anonymous
variable “_” (underscore) behaves
like a normal variable but will always match anything,
since it is never instantiated. This allows you to specify
a “don't care” condition. For example, going back to our
database of composers, the pattern:
{
composer => 'COMPOSER',
initials => '_',
lived => '_'
}
will just retrieve all of the composers names
from the database, without testing or instantiating any other variables.
Not also that since “_” always matches, and
is never instantiated, it can be reused throughout a pattern.
This unifier is a direct modification of the pattern matcher from
the previous section, so let's just concentrate on the
differences. Firstly match() has been renamed
to unify(), and it has an extra clause, in case the
old structure, which is now also a pattern, contains
variables. The various match_* subs have
also been renamed unify_*, and the variables
$pattern and $struct,
now both patterns, have been renamed to just
$a and $b:
sub unify {
my ($a, $b, $env) = @_;
$env ||= {};
if (var($a)) {
unify_var($a, $b, $env);
} elsif (var($b)) {
unify_var($b, $a, $env);
} elsif (hashes($a, $b)) {
unify_hashes($a, $b, $env);
} elsif (arrays($a, $b)) {
unify_arrays($a, $b, $env);
} elsif (strings($a, $b)) {
unify_strings($a, $b, $env);
} else {
fail();
}
return $env;
}
The extra clause, if $b is a var, simply reverses
the order of the arguments to unify_var(). Note that
the single environment means that variables will share across
the two patterns. If you don't want this, simply make sure that
the two patterns don't use the same variable names.
unify_hashes(), unify_arrays() and unify_strings()
are identical to their match_* equivalents, except that
unify_arrays() and unify_hashes() call
unify() instead of match() on their components.
The var() check is slightly different, to allow for the
anonymous variable:
sub var {
my ($thing) = @_;
!ref($thing) && ($thing eq '_' || $thing =~ /^[A-Z]/);
}
That leaves unify_var(), where the action is.
unify_var() is still quite similar to match_var(), it just
has more things to watch out for:
sub unify_var {
my ($var, $other, $env) = @_;
if (exists($env->{$var})) {
unify($env->{$var}, $other, $env);
} elsif (var($other) && exists($env->{$other})) {
unify($var, $env->{$other}, $env);
} elsif ($var eq '_') {
return;
} else {
$env->{$var} = $other;
}
}
So $struct was renamed to $other, and
unify_var() calls unify() instead of match().
If $var is not set in the environment, instead of immediately
assuming it can match $other, unify_var() looks to
see if $other is a var and already has a value. If so it
calls unify() on $var and the value of $other.
If $other is not a var, or has no binding, unify_var()
next checks
to see if $var is the anonymous variable. If it is, then
because the anonymous variable always matches and is never instantiated,
it just returns. Lastly, only when all
other options have been tried, it adds a binding from the $var
to $other and returns.
Let's walk through the actions of unify() as it attempts to
unify the two patterns ['f', ['g', 'A'], 'A'] and
['f', 'B', 'abc'].
-
unify(['f', ['g', 'A'], 'A'], ['f', 'B', 'abc'], {})
is called with the two complete patterns
and an empty environment,
and determines that both patterns are arrays, so calls
unify_arrays().
-
unify_arrays(['f', ['g', 'A'], 'A'], ['f', 'B', 'abc'], {})
simply calls unify() on
each component.
-
unify('f', 'f', ())
determines that both its arguments are
strings, and calls unify_strings().
-
unify_strings('f', 'f', {}) = {}
succeeds but the environment
is unchanged.
-
unify(['g', 'A'], 'B', {})
determines that it's second
argument is a variable and so calls unify_var()
with the arguments reversed.
-
unify_var('B', ['g', 'A'], {}) = {B => ['g', 'A']}
succeeds, and unify_var()
extends the environment with 'B'
bound to ['g', 'A'].
-
unify('A', 'abc', {B => ['g', 'A']})
determines that it's first argument is
a variable and so calls unify_var() again,
passing the environment that was extended by the
previous call to unify_var().
-
unify_var('A', 'abc', {B => ['g', 'A']}) = {B => ['g', 'A'], A => 'abc'}
also succeeds, extending the
environment with a new binding of 'A' to
'abc'. This environment is the final result
of the entire unification.
So the final result {B => ['g', 'A'], A => 'abc'} falls
a little short of our expectations, because the value for 'B'
still contains a reference to the variable 'A'. However this is not a problem as such. we can
patch up the result with a separate routine called resolve().
sub resolve {
my ($pattern, $env) = @_;
while (var($pattern)) {
if (exists $env->{$pattern}) {
$pattern = $env->{$pattern};
} else {
return $pattern;
}
}
if (hash($pattern)) {
my $ret = {};
foreach my $key (keys %$pattern) {
$ret->{$key} = resolve($pattern->{$key}, $env);
}
return $ret;
} elsif (array($pattern)) {
my $ret = [];
foreach my $item (@$pattern) {
push @$ret, resolve($item, $env);
}
return $ret;
} else {
return $pattern;
}
}
resolve() takes a pattern, and the environment that
was returned by unify(). If and while the pattern
is a variable, it repeatedly replaces it with its value from the
environment, returning the variable if it cannot further resolve it.
Then if the result is a hash or an array reference,
resolve() recursively calls itself on each component of the
result, also passing the environment. The final result of
resolve() is a structure where any variables in the pattern
that have
values in the environment have been replaced by those values.
Note that resolve() does not change the environment in
any way.
This completes our stand-alone implementation of unify().
Hopefully seeing it out in the open like this will make the
subsequent implementation within PScheme easier to digest.
It is a little difficult to demonstrate the utility of
unify() at this point, since it's purpose is mostly
part of the requirements of logic programming, however
to give you some idea, consider that the result of one unification,
an environment or hash, can be passed as argument to a second
unification, thus constraining the values that the pattern
variables in the second unification can potentially take.
There is one extremely interesting and useful application
of unification outside of logic programming which makes
use of this idea. Consider that we might
want to check that the types of the variables in a PScheme
expression are correct before we eval the expression.
Assume that we know the types of the arguments and return values
from all primitives in the language. Furthermore we
can also detect the types of any
variables which are assigned constants directly.
It is therefore possible to detect
if a variable's assigned value does not match it's eventual
use, even if that eventual use is remote (through layers of
function calls) from the original assignment.
Such a language, which does not declare types but is nonetheless
capable of detecting type mismatches, is called an implicitly
typed language.
We can use unification to do this type checking, by treating PScheme
variables as pattern variables and unifying them with their
types and with each other across function calls,
accumulating types of arguments and return values for
lambda expressions and functions in the process.
That however, is for another chapter.
Next we're going to look at the implementation
of unify in PScheme.
17.3.2. Implementing unify in PScheme
To get the ball rolling with the implementation
of unify, notice that the previous implementation
of unify() frequently tests the types of its arguments.
Obviously in an object-oriented implementation like PScheme we can
distribute a Unify() method around the various data types
and avoid this explicit type checking for the most part.
A second point worth noting is that where the above unify()
did a die on failure, our new Unify() can quite
reasonably invoke backtracking instead, to try another option,
which fits in quite neatly
with our existing amb implementation.
A third and final point. unify() above made use of a flat
hash to keep track of variable bindings, but PScheme already has a
serviceable environment implementation and we should make use of
it. This will mean exposing the environment as a PScheme data type
since that is what is explicitly passed to and returned by
Unify(), but this is not a concern since we have done this
once before in our classes and objects extension from Chapter 12.
We'd better start by looking at the unify command in
action in the interpreter. The result of a call to unify
is a PScm::Env which isn't much direct use. However we can
add another PScheme command that will help us out there.
substitute takes a form and an environment, and replaces
any pattern variables in the
form with their values from the argument environment. It
also performs the resolve() function on each value before
substitution. So for example:
> (substitute
> '(f B A)
> (unify '(f (g A) A)
> '(f B abc)))
(f (g abc) abc)
The call to unify provides the second argument, an
environment, to substitute, which then performs the
appropriate replacements on the expression (f B A)
to produce the result (f (g abc) abc). Note that in
all cases we have to quote the expressions to prevent them
from being evaluated. We do need the interpreter to evaluate the arguments
to substitute and unify in most cases
however, because the
actual forms being substituted and unified may be passed
in as (normal PScheme) variables or otherwise calculated.
I should probably also demonstrate that
unify does proper backtracking if it fails:
> (unify '(a b c) '(a b d))
Error: no more solutions
It's still somewhat difficult to demonstrate the usefulness
of unify combined with amb at this stage however.
That will have to wait until
the next section
where we finally get to see logic programming in action.
The first thing we need to do then, is to create a new special form
PScm::SpecialForm::Unify and give it an Apply()
method. This special form will be bound to the symbol unify
in the top-level environment. unify will take two or three
arguments. The first two arguments are the patterns to be unified. The third,
optional argument is an environment to extend. If unify
is not passed an environment, it will create a new, empty one.
We have to make unify a special form because it needs access
to the failure continuation. Here's
PScm::SpecialForm::Unify:
504 package PScm::SpecialForm::Unify;
505
506 use base qw(PScm::SpecialForm);
507
508 use PScm::Continuation;
509
510 sub Apply {
511 my ($self, $form, $env, $cont, $fail) = @_;
512 $form->map_eval(
513 $env,
514 cont {
515 my ($evaluated_args, $fail) = @_;
516 my ($a, $b, $qenv) = $evaluated_args->value;
517 $qenv ||= new PScm::Env();
518 $a->Unify($b, $qenv, $cont, $fail);
519 },
520 $fail
521 );
522 }
523
524 1;
You can see that it uses map_eval()
from Section 13.6.5
to evaluate its argument
$form, passing it a continuation that breaks out the
patterns $a and $b, and the optional environment
$qenv from the evaluated arguments. Then
it defaults $qenv to a new, empty environment,
and calls Unify() on $a passing it the other pattern,
the query environment and the success and failure continuations.
Referring back to our test implementation of unify() in
Section 17.3.1
we can see that the first thing that implementation does is to check if its first
argument is a var, and if so call unify_var() on it.
We can replace this explicit conditional with polymorphism
by putting a Unify() method at an appropriate place
in the PScm::Expr hierarchy. But the
PScm::Expr::Symbol class is not the best place:
not all symbols are pattern variables, only those starting
with capital letters or underscores. So here's the trick.
We create a new subclass of PScm::Expr::Symbol
called PScm::Expr::Var and put the method there.
Read() can detect pattern variables on input and create
instances of this new class instead of PScm::Expr::Symbol.
Since the new class inherits from PScm::Expr::Symbol,
and we do not override any of that class's existing methods,
these new PScm::Expr::Var objects behave exactly
like ordinary symbols to the rest of the PScheme implementation.
Here's the change to _next_token()
from PScm::Read to make this happen.
66 sub _next_token {
67 my ($self) = @_;
68
69 while (!$self->{Line}) {
70 $self->{Line} = $self->{FileHandle}->getline();
71 return undef unless defined $self->{Line};
72 $self->{Line} =~ s/^\s+//s;
73 }
74
75 for ($self->{Line}) {
76 s/^\(\s*// && return PScm::Token::Open->new();
77 s/^\)\s*// && return PScm::Token::Close->new();
78 s/^\'\s*// && return PScm::Token::Quote->new();
79 s/^\,\s*// && return PScm::Token::Unquote->new();
80 s/^\.\s*// && return PScm::Token::Dot->new();
81 s/^([-+]?\d+)\s*//
82 && return PScm::Expr::Number->new($1);
83 s/^"((?:(?:\\.)|([^"]))*)"\s*// && do {
84 my $string = $1;
85 $string =~ s/\\//g;
86 return PScm::Expr::String->new($string);
87 };
88 s/^([A-Z_][^\s\(\)]*)\s*//
89 && return PScm::Expr::Var->new($1);
90 s/^([^\s\(\)]+)\s*//
91 && return PScm::Expr::Symbol->new($1);
92 }
93 die "can't parse: $self->{Line}";
94 }
The only change is on
Lines 88–89
where if the token matched starts with a capital letter or underscore
then _next_token() returns a new PScm::Expr::Var where otherwise
it would have returned a PScm::Expr::Symbol.
Now we have somewhere to hang the functionality equivalent to
unify_var() from our test implementation, we can put it
in a method called Unify() in PScm::Expr::Var:
378 sub Unify {
379 my ($self, $other, $qenv, $cont, $fail) = @_;
380
381 if (defined(my $value = $qenv->LookUpNoError($self))) {
382 $value->Unify($other, $qenv, $cont, $fail);
383 } elsif ($other->is_var &&
384 defined (my $other_value = $qenv->LookUpNoError($other))) {
385 $other_value->Unify($self, $qenv, $cont, $fail);
386 } elsif ($self->is_anon) {
387 $cont->Cont($qenv, $fail);
388 } else {
389 $qenv->ExtendUnevaluated(
390 new PScm::Expr::List($self),
391 new PScm::Expr::List($other),
392 $cont,
393 $fail
394 );
395 }
396 }
It's identical to the earlier unify_var() except that it
makes use of method calls and is written in CPS. The is_var()
method is defined to be false at the root of the expression
hierarchy in PScm::Expr, but is overridden to be true in
PScm::Expr::Var alone. Equivalently is_anon()
is defined false in PScm::Expr but defined to be true
if the value of the var is “_” in
PScm::Expr::Var:
400 sub is_anon {
401 my ($self) = @_;
402 $self->value eq '_';
403 }
The only other occurrence of Unify() is at the root
of the hierarchy in PScm::Expr:
49 sub Unify {
50 my ($self, $other, $qenv, $cont, $fail) = @_;
51 if ($other->is_var) {
52 $other->Unify($self, $qenv, $cont, $fail);
53 } else {
54 $self->UnifyType($other, $qenv, $cont, $fail);
55 }
56 }
This really just takes care of the case where the first pattern
is not a var but the second pattern is. If the second pattern is a var
it calls Unify() on it, passing $self as the argument,
reversing the order in the same way as our prototype unify() did.
If the second pattern is not a var, then it calls a new method
UnifyType() on $self. UnifyType() is just
another name for Unify() and allows a second crack at
polymorphism since it is implemented separately in a couple of places
in the PScm::Expr hierarchy.
The first such place is in PScm::Expr itself.
58 sub UnifyType {
59 my ($self, $other, $qenv, $cont, $fail) = @_;
60 if ($self->Eq($other)) {
61 $cont->Cont($qenv, $fail);
62 } else {
63 $fail->Fail();
64 }
65 }
This works for all atomic data types. If the two patterns are Eq()
then succeed, otherwise fail. This is the first place we've actually seen
the failure continuation invoked. Note that the equality test Eq()
implicitly deals with type equivalence for us, so we don't need the
arrays() routines etc. from the prototype.
Now the only other place we need to
put UnifyType() is in PScm::Expr::List::Pair
276 sub UnifyType {
277 my ($self, $other, $qenv, $cont, $fail) = @_;
278 if ($other->is_pair) {
279 $self->[FIRST]->Unify(
280 $other->[FIRST],
281 $qenv,
282 cont {
283 my ($qenv, $fail) = @_;
284 $self->[REST]->Unify(
285 $other->[REST],
286 $qenv,
287 $cont,
288 $fail
289 );
290 },
291 $fail
292 );
293 } else {
294 $fail->Fail();
295 }
296 }
This PScm::Expr::List::Pair::UnifyType() is in fact simpler
in one sense than the unify_arrays() from our test implementation.
First it performs a simple check that the $other is a list.
If not it calls the failure continuation. Then,
rather than walking both lists, it only needs to call Unify()
on its first() and rest(), passing the $other's
first() or rest() appropriately. Of course this is a
little complicated because it's in CPS, but nonetheless that is
all it has to do.
That's all for unify itself. If you remember from the start
of this section, we will also need a substitute builtin to
replace pattern variables with values in the environment. It is called
like (substitute ‹pattern› ‹env›)
and returns the ‹pattern› suitably
instantiated. We can make this a primitive rather than a
special form because it has no need of an environment (other than
the one that is explicitly passed) and no need to access the failure
continuation (it always succeeds). Here's
PScm::Primitive::Substitute:
216 package PScm::Primitive::Substitute;
217
218 use base qw(PScm::Primitive);
219
220 sub _apply {
221 my ($self, $body, $qenv) = @_;
222 $body->Substitute($qenv->ResolveAll());
223 }
It does nothing much by itself, merely calling a ResolveAll()
method on the argument environment then passing the result to the
$body's Substitute() method. We'll take a look at
that new PScm::Env::ResolveAll() method first.
266 sub ResolveAll {
267 my ($self) = @_;
268 my %bindings;
269 foreach my $var ($self->Keys) {
270 $bindings{$var} = $self->Resolve(new PScm::Expr::Var($var));
271 }
272 return $self->new(%bindings);
273 }
This ResolveAll() loops over each key in the environment,
calling a subsidary Resolve() method on each and saving the
result in a temporary %bindings hash. Then it creates
and returns a new PScm::Env with those bindings.
If you refer back to our resolve() function in the
prototype, you can see that in the first stage, if the $pattern
is a variable, it repeatedly attempts to replace it with a value
from the environment until either it is not a variable anymore or
it cannot find a value. This ResolveAll() is effectively
pre-processing the environment so that any subsequent lookup
for a pattern variable will not need to perform that iteration.
Keys() just collects all the keys from the environment:
275 sub Keys {
276 my ($self, $seen) = @_;
277 $seen ||= {};
278 foreach my $key (keys %{$self->{bindings}}) {
279 $seen->{$key} = 1;
280 }
281 if ($self->{parent}) {
282 $self->{parent}->Keys($seen);
283 }
284 return (keys %$seen);
285 }
and Resolve() does exactly what resolve() did in
our test implementation: it repeatedly replaces the variable with
its value from the environment until the variable is not a variable
any more, or cannot be found. If it finds a non-variable value it
calls its ResolveTerm() method on it, passing the env
$self as argument, and returning the result.
287 sub Resolve {
288 my ($self, $term) = @_;
289 while ($term->is_var) {
290 if (my $val = $self->LookUpNoError($term)) {
291 $term = $val;
292 } else {
293 return $term;
294 }
295 }
296 return $term->ResolveTerm($self);
297 }
ResolveTerm() gives any compound term a chance to
resolve any pattern variables it may contain. There are two
definitions of ResolveTerm().
The only compound terms in PScheme are lists, and pattern
variables themselves have already been resolved, so the default
ResolveTerm() in PScm::Expr just returns
$self:
67 sub ResolveTerm {
68 my ($self, $qenv) = @_;
69 return $self;
70 }
The second definition of ResolveTerm() is, not
surprisingly, in PScm::Expr::List::Pair:
298 sub ResolveTerm {
299 my ($self, $qenv) = @_;
300 return $self->Cons($qenv->Resolve($self->[FIRST]),
301 $qenv->Resolve($self->[REST]));
302 }
It walks itself, calling the argument $qenv's
Resolve() method on each component, and returning
a new PScm::Expr::List of the results.
So we're talking about how substitute works, and we
saw that primitive's _apply() method called the argument
$qenv's ResolveAll() method to return a new environment
with any pattern variables in the values replaced, where possible.
Then _apply() passed that
new environment to its argument $body's Substitute()
method. We've just seen how ResolveAll() works, now we can
look at Substitute() itself.
Only pattern variables can be substituted, but lists
need to examine themselves to see if they contain any pattern
variables. So a default Substitute() method
in PScm::Expr takes care of all the things that can't
be substituted, it just returns $self:
72 sub Substitute {
73 my ($self, $qenv) = @_;
74 return $self;
75 }
The Substitute() in PScm::Expr::Var
returns either its value from the environment or itself if it
is not in the environment:
405 sub Substitute {
406 my ($self, $qenv) = @_;
407 return $qenv->LookUpNoError($self) || $self;
408 }
Finally, the Substitute() in PScm::Expr::List::Pair
recursively calls Substitute() on each of its
components, constructing a new list of the results:
304 sub Substitute {
305 my ($self, $qenv) = @_;
306 return $self->Cons($self->[FIRST]->Substitute($qenv),
307 $self->[REST]->Substitute($qenv));
308 }
And that's substitute. To sum up, it tries as hard as
it can to replace all pattern variables in the form with values
from the environment, recursing not only into the form it is
substituting, but also into the values of the variables themselves.
There are a few more things we need to add to the interpreter
before we can show off its new prowess. Firstly we will have occasion to pass
an empty environment into unify (indirectly), and for that we'll need
a new-env primitive. This is as simple as it gets:
258 package PScm::Primitive::NewEnv;
259
260 use base qw(PScm::Primitive);
261
262 sub _apply {
263 new PScm::Env();
264 }
Another thing we'll need goes back to a passing comment
I made a while back. It can be a problem if you try to unify
two patterns that inadvertantly use the same pattern variable
names. Sometimes you want the variables to share a value, and
sometimes you don't. For this reason we need something that will
take a pattern and replace its variable names with new variable names
that are guaranteed to be unique. The same variable occurring
more than once in the pattern should correspond to the same new
variable occurring more than once in the result, but we should be
reasonably confident that the new variable name won't appear anywhere
else in the program by accident.
This new PScheme function is called instantiate.
It could be written in the PScheme language, but that would require
adding other less germane primitives for creating symbols etc. so
all in all it is probably better to build it in to the core.
It can be a primitive, but it will need a bit more than just
an _apply() method:
267 package PScm::Primitive::Instantiate;
268
269 use base qw(PScm::Primitive);
270
271 sub new {
272 my ($class) = @_;
273 bless {
274 seen => {},
275 counter => 0,
276 }, $class;
277 }
278
279 sub _apply {
280 my ($self, $body) = @_;
281 $self->{seen} = {};
282 $body->Instantiate($self);
283 }
284
285 sub Replace {
286 my ($self, $var) = @_;
287 return $var if $var->is_anon;
288 unless (exists($self->{seen}{$var->value})) {
289 $self->{seen}{$var->value} =
290 new PScm::Expr::Var($self->{counter}++);
291 }
292 return $self->{seen}{$var->value};
293 }
294
295 1;
Remember that there is only one instance of any given
primitive or special form in the PScheme environment, and that
persists for the duration of the repl. So by giving
this primitive its own new() method we provide a
convenient place to store a singleton counter that we can
use to generate new symbols. The seen field of the
object however, which keeps track of which variables the
instantiate function has already encountered,
must be re-initialized to an empty hash on each separate
application of the primitive.
After (re-)initializing seen
on Line 281,
_apply() calls its argument $body's
Instantiate()
method passing $self as argument.
Obviously the only PScm::Expr
type that will avail itself of the instantiate object is
PScm::Expr::Var, and that will make use
of the callback method Replace() to find or
generate a replacement variable.
Replace() then, first checks to see if
the variable is the anonymous variable
(Line 287).
If so then it just returns the variable, since the
anonymous variable never shares and should never be
replaced by a variable that will share. Then unless
it has already seen the variable it creates a new
alias for it by using the incrementing counter
(Lines 288–291).
This works well because the reader would never
create a PScm::Expr::Var from a number.
Just as with Unify() and Substitute(),
a default method Instantiate() in PScm::Expr
handles most cases and just returns $self:
79 sub Instantiate {
80 my ($self, $instantiator) = @_;
81 return $self;
82 }
The PScm::Expr::Var version of instantiate
calls the $instantiator's Replace()
callback to get a new variable, passing $self
as argument because Replace() needs to keep
track of the variables it has seen already:
412 sub Instantiate {
413 my ($self, $instantiator) = @_;
414 return $instantiator->Replace($self);
415 }
Finally PScm::Expr::List::Pair::Instantiate()
recurses on both its first() and rest()
components, calling Instantiate() on both
and constructing a new list on the way back out:
316 sub Instantiate {
317 my ($self, $instantiator) = @_;
318 return $self->Cons($self->[FIRST]->Instantiate($instantiator),
319 $self->[REST]->Instantiate($instantiator));
320 }
The last thing we're going to need, for pragmatic reasons,
is a way to
check the type of various expressions from within the
PScheme language. A proper scheme implementation has a full
set of such type checking functions, but we're only going
to need pair?, number? and var?
(note the question marks.) They are all primitives, and in
fact have so much in common that we will create an abstract
parent class called PScm::Primitive::TypeCheck
and put a shared _apply() method in there:
226 package PScm::Primitive::TypeCheck;
227
228 use base qw(PScm::Primitive);
229
230 sub _apply {
231 my ($self, $body) = @_;
232 if ($self->test($body)) {
233 return new PScm::Expr::Number(1);
234 } else {
235 return new PScm::Expr::Number(0);
236 }
237 }
You can see that it calls a test() method which we
must subclass for each test, then it returns an appropriate
true or false value depending on the test. Here's the test
for pair? in PScm::Primitive::TypeCheck::Pair:
240 package PScm::Primitive::TypeCheck::Pair;
241 use base qw(PScm::Primitive::TypeCheck);
242
243 sub test { $_[1]->is_pair }
We've already seen that is_pair() is defined false in
PScm::Expr and overridden to be true in
PScm::Expr::List::Pair alone. The equivalent
number? and var? PScheme functions
are bound to PScm::Primitive::TypeCheck::Number
and PScm::Primitive::TypeCheck::Var, and make
use of equivalent is_number() and is_var()
methods in PScm::Expr.
We have now implemented the four components we need to get on
with defining a logic programming language: unify,
substitute, new-env and
instantiate. Along with those we have also added
the three type tests pair?, var? and number?
which just check if their argument is of that type.
They are all wired in to the repl in the normal way, here's the
additions:
36 sub ReadEvalPrint {
37 my ($infh, $outfh) = @_;
38
39 $outfh ||= new FileHandle(">-");
40 my $reader = new PScm::Read($infh);
41 my $initial_env;
42 $initial_env = new PScm::Env(
43 let => new PScm::SpecialForm::Let(),
44 '*' => new PScm::Primitive::Multiply(),
45 '-' => new PScm::Primitive::Subtract(),
46 '+' => new PScm::Primitive::Add(),
47 if => new PScm::SpecialForm::If(),
48 lambda => new PScm::SpecialForm::Lambda(),
49 list => new PScm::Primitive::List(),
50 car => new PScm::Primitive::Car(),
51 cdr => new PScm::Primitive::Cdr(),
52 cons => new PScm::Primitive::Cons(),
53 letrec => new PScm::SpecialForm::LetRec(),
54 'let*' => new PScm::SpecialForm::LetStar(),
55 eval => new PScm::SpecialForm::Eval(),
56 macro => new PScm::SpecialForm::Macro(),
57 quote => new PScm::SpecialForm::Quote(),
58 'set!' => new PScm::SpecialForm::Set(),
59 begin => new PScm::SpecialForm::Begin(),
60 define => new PScm::SpecialForm::Define(),
61 'make-class' => new PScm::SpecialForm::MakeClass(),
62 'call/cc' => new PScm::SpecialForm::CallCC(),
63 print => new PScm::SpecialForm::Print($outfh),
64 spawn => new PScm::SpecialForm::Spawn(),
65 exit => new PScm::SpecialForm::Exit(),
66 error => new PScm::SpecialForm::Error(
67 $outfh,
68 bounce { repl($initial_env, $reader, $outfh) }
69 ),
70 amb => new PScm::SpecialForm::Amb(),
71 'eq?' => new PScm::Primitive::Eq(),
72 '>' => new PScm::Primitive::Gt(),
73 '<' => new PScm::Primitive::Lt(),
74 '>=' => new PScm::Primitive::Ge(),
75 '<=' => new PScm::Primitive::Le(),
76 and => new PScm::SpecialForm::And(),
77 or => new PScm::SpecialForm::Or(),
78 unify => new PScm::SpecialForm::Unify(),
79 substitute => new PScm::Primitive::Substitute(),
80 'new-env' => new PScm::Primitive::NewEnv(),
81 instantiate => new PScm::Primitive::Instantiate(),
82 'pair?' => new PScm::Primitive::TypeCheck::Pair(),
83 'var?' => new PScm::Primitive::TypeCheck::Var(),
84 'number?' => new PScm::Primitive::TypeCheck::Number(),
85 );
86
87 $initial_env->Define(
88 PScm::Expr::Symbol->new("root"),
89 PScm::Class::Root->new($initial_env)
90 );
91 __PACKAGE__->new_thread(bounce { repl($initial_env, $reader, $outfh) });
92 trampoline();
93 }