
Another recent idea I’ve had is to build a compiler for a pscheme-like language (different syntax, extended functionality) that would target an abstract machine much as Java does (I know Java calls it a “Virtual Machine” but that’s an accident of history since Java originally targeted a real CPU and the replacement machine was a “virtualisation” of that.) I started looking at Parrot, but Parrot has built-in support for a single continuation only, and would make a second “failure” continuation doubly difficult to implement.
So I started thinking about building my own. The real joy of this is that I can prototype it in a high-level language like Perl, then re-write it into something fast like C or C++ later. I actually have a (mostly) working version in Perl for PScheme that runs about seven times faster than the interpreter, but it has issues.
Anyway I think the basic ideas are sound. In an interpreter a closure is a function plus an environment. In a compiled language that’s even simpler, a “function” is just a machine address, so a closure is a pair of addresses: address of environment on the heap and address of machine instruction in the core. A Success Continuation on the other hand has a lot more context. It contains the return address and the old environment, but also must restore any temporary variables, along with the previous continuation that will be returned to later. Finally a Failure continuation is a complete reset. It does not preserve any data when it is invoked, but completely restores the Abstract machine to a previous state.
So without further ado, here’s my abstract machine:
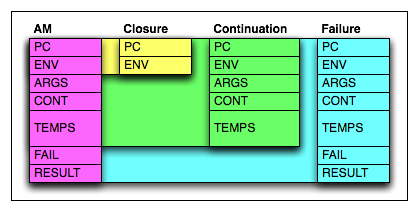
- PC
- is just an integer index into the machine code table.
- ENV
- is the address of the current run-time environment (the compiler has pre-determined the locations of the data in the environment, the run time environment contains only the data.)
- ARGS
- would point to an array or linked list of actual arguments to a closure, before they are bound into an environment. They constitute the nearest lexical scope once inside the closure.
- CONT
- points at the most recent Continuation.
- TEMPS
- is just an arbitrarily sized array of temporary registers, their utility is questionable as there is no efficiency saving as there would be for a real CPU, but it makes the model closer to a standard compilation target.
- FAIL
- points at the most recent Failure continuation.
- RESULT
- is where a return value is passed to a Continuation.
Usefully, the different subcomponents (Closure, Continuation and Failure) are all contiguous, so invoking any of them is just a singlememcpy() from the stored object (on the heap) to the “cpu”. I don’t know if this is just blind luck or something deeper.
For each subcomponent there would be two abstract machine instructions: one to set up a new structure and one to invoke it. Specifically:
- Closure
-
create_closure(PC, ENV)- create a new closure object (and put it in TEMPS somewhere)
call_closure()memcpy(&AM, AM.TEMPS[n], sizeof(struct closure))
- Continuation
-
create_continuation(PC)- allocate a new continuation struct, copy the relevant components of the AM into it, assign the PC to it directly, point
AM.CONTat the new continuation. continue()memcpy(&AM, AM.CONT, sizeof(struct continuation))
- Failure
- completely analagous to Continuation above.
So the plan is:
- Write the Abstract Machine in C or C++.
- Write an interpreter for the new language in Perl.
- Write a compiler for the new language in itself.
- Run the interpreted compiler on its own source code to produce bytecode for the compiler.
- Compile the compiler again using the bytecode compiler and diff the bytecodes: any difference is a problem.
- World domination.
So far, I have a parser and a partial interpreter for a new language called “F-Natural”: If you think of ML but with real Unification, backtracking and a javasript-like syntax you will get the basic idea. I’m still a long way from world domination but we live in hope. I may post some code here later.