I confess, I’ve never done MVC before! I’ve heard about it and read about it of course, but just never had occasion to use it until now.
I run our arechery club’s website as a sort of a passtime. It’s enjoyable and relaxing and I’m not under any pressure to deliver anything. So I thought I would do a sightmarks calculator.
In case you’re not familiar with the finer points of archery, most bows have a sight attached. The sight is a vertical track marked in arbitrary units that sticks out in front of the bow and has a scope or a pin that can slide up and down the track for different distances. Archers have a little book of sightmarks that they keep, and write down their sightmark for each distance. Now the amazing thing is that all that physics of ballistics and mathematics of trajectories seems to cancel itself out, so that there is a simple linear (or very nearly linear) relation between sightmark and distance.
All I wanted to achieve then, was a simple tool where an archer could enter a set of sightmarks and get a line of best fit for the data, which could then be used to generate a set of estimated sight marks for all the standard distances.
The tool would have an input section for the sample sightmarks, a graph (canvas) showing the inputs and line of best fit, and a table of the resulting estimates.
It’s only slightly more complicated than that in practice because I wanted to be able to persist the data in the browser’s local storage, and to allow archers to save multiple sets of sightmarks for different bows, arrows and bow setups.
This is obviously screaming out for MVC. I didn’t want to add a dependency on any heavyweight javascript MVC framewaork, so I decided to write it from scratch. You can see the finished result at www.roystonarchery.org/new/sightmarks/ (apologies for the very slow site, it’s EIG.)
The basic idea of MVC is a Model which stores state, one or more Views which present the model to the user, and a Controller which allows manipulation of the model. Conceptually it’s as simple as:
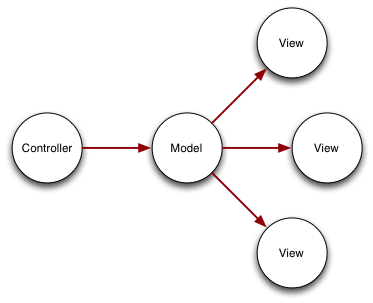
I should point out that this is the original MVC pattern as espoused by SmallTalk80, not the more “modern” variants fitted to the web, but since this is a browser-only application that seems a reasonable choice of pattern.
Of course real world programming is not that simple, and it took me an unreasonable amount of time to get this working. First of all I needed two controllers. The first would deal with the editing of the current model: adding and removing sight marks. The second controller would be concerned with persisting the data to local storage, restoring the data from local storage, and generally managing that data. The final architecture I came up with looks like this:
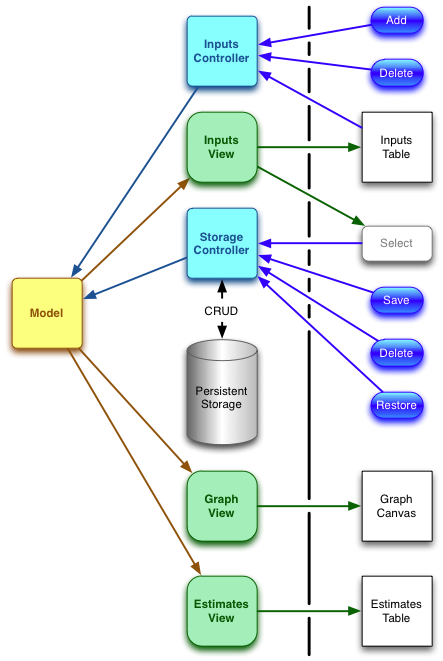
The heavy vertical line demarcates user-visible components from the “back-end”.
It works quite well now, but I had a struggle to get there. Maybe it’s because I don’t know Javascript that well, and I’m only just learning jQuery and the DataTables API, but I think it’s more fundamental, that the MVC “pattern” is fundamentally flawed in that it is usually impossible not to blur the distinction between Model and Controller, or in my case between View and Controller.
The Storage Controller is fairly straightforward. It reacts to user input by saving and restoring the entire Model, and allows management of the storage directly (deleting unwanted sets of sightmarks.)
The Input controller was more difficult because it needs to take information from the displayed inputs (currently selected sightmark) in order to delete it from the model. I had to make some rules to stop the whole thing dissolving into mush.
Lessons Learned
The most important thing is to ensure that the only state kept is in the model. If there is any unavoidable secondary state (such as is maintained by the DataTables objects,) then that secondary state must be completely flushed and recreated by any change to the model, and should not be relied upon.
The second important thing is to resist the temptation to short-circuit the system by having controllers update views directly. To keep this thing sane, all communication between controller and view must go via the model.
Lastly, having a MVC structure is better than having no structure, but be prepared to have to twist things around to make it work.
MVC is a very old pattern, dating to the earliest SmallTalk systems in an age where user experience could take second place to a clean implementation. Nowadays the UX is paramount, and we may have to think again.